7 P% u$ U6 T9 }, c% G" x 匹配行结束符。例如正则表达式weasel$ 能够匹配字符串"He's a weasel"的末尾,但是不能匹配字符串"They are a bunch of weasels."。 , Y0 _! B$ ^. _6 l' u8 ~
5 ]3 \" e3 f& B/ A, o
^2 x" ~0 O# N8 B9 z$ K
% z9 N" S1 ^ `6 {, u
匹配一行的开始。例如正则表达式^When in能够匹配字符串"When in the course of human events"的开始,但是不能匹配"What and When in the"。3 f, o2 T6 b4 a R* [
1 _+ g' l5 d1 d3 y0 ~0 t* b1 U
*" |% a5 W8 O1 V+ ~& m. W) D
0 C1 t0 w- u; C3 D/ N 匹配0或多个正好在它之前的那个字符。例如正则表达式.*意味着能够匹配任意数量的任何字符。 / Z! K/ |5 {# B9 U8 H2 z! B) B0 l3 t) O5 R
\( Y* z2 Y+ _3 H; B, c
8 H8 f: B8 _" U- N- G* @: l 这是引用符,用来将这里列出的这些元字符当作普通的字符来进行匹配。例如正则表达式\$被用来匹配美元符号,而不是行尾,类似的,正则表达式\.用来匹配点字符,而不是任何字符的通配符。% b; w5 q+ w& A5 o m& G
- y+ A8 H0 ]1 k. O K [ ] ) S8 x9 M* j/ T! C! y1 e! G / ]' R7 g; |5 h9 k [c1-c2]9 B1 u2 \( b- v0 O
( a6 @9 }! P/ v( { E [^c1-c2]7 G+ c' b& e: n" T1 \# {% T) Y
" I u) a. \& K/ x9 o% d
匹配括号中的任何一个字符。例如正则表达式r[aou]t匹配rat、rot和rut,但是不匹配ret。可以在括号中使用连字符-来指定字符的区间,例如正则表达式[0-9]可以匹配任何数字字符;还可以制定多个区间,例如正则表达式[A-Za-z]可以匹配任何大小写字母。另一个重要的用法是“排除”,要想匹配除了指定区间之外的字符——也就是所谓的补集——在左边的括号和第一个字符之间使用^字符,例如正则表达式[^269A-Z] 将匹配除了2、6、9和所有大写字母之外的任何字符。6 \+ w! Z, l I& s" [$ L0 g
% t8 l/ b6 e+ V \< \> / r/ V# f/ i2 ?( x) ]- Z( M5 S8 K, S- \2 F+ f$ ~' s& G n8 [) U: b
匹配词(word)的开始(\<)和结束(\>)。例如正则表达式\<the能够匹配字符串"for the wise"中的"the",但是不能匹配字符串"otherwise"中的"the"。注意:这个元字符不是所有的软件都支持的。1 T+ G% J) }/ V7 [
% u& \& I) d) F0 Y7 L, R/ f7 \
\( \) ; V, f) v8 g7 h( D 2 l. T, T' p# R8 L0 M0 f5 x7 p& U 将 \( 和 \) 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 到 的符号来引用。 ; E' U- ~" B5 O9 C( X N " p) U' h' n' U: Y, W | 2 m3 q& x: ~& J# I; ^) H2 d' a! p; ]7 I9 o8 Z4 e* n6 [( h& |
将两个匹配条件进行逻辑“或”(Or)运算。例如正则表达式(him|her) 匹配"it belongs to him"和"it belongs to her",但是不能匹配"it belongs to them."。注意:这个元字符不是所有的软件都支持的。 + |: s4 i% }3 N& _, ^! o. C- u- V! \7 T" e- A
+: U1 _2 E5 P- V
9 S. I. C7 n, n8 \
匹配1或多个正好在它之前的那个字符。例如正则表达式9+匹配9、99、99、9999、99999、……(一个或一个以上“9”)。注意:这个元字符不是所有的软件都支持的。3 U! [- q( Q8 W. i/ w! y
+ x" O: O1 k: I1 q; P
? 5 A6 I P2 V8 X8 f2 I: c1 [7 G- i$ k% L! e$ z
匹配0或1个正好在它之前的那个字符。注意:这个元字符不是所有的软件都支持的。 % M0 m' f; ], ]/ Z- u8 K 9 U$ \0 N2 |" n8 z \{i\} ; n6 P& k8 p0 F& l% o% j" c: p2 }3 g$ w- L
\{i,j\} % K4 C! @3 L) Q. l- k: v8 Q7 `: G% l% ?- S8 |6 c, I; Q) P9 t
匹配指定数目的字符,这些字符是在它之前的表达式定义的。例如正则表达式A[0-9]\{3\} 能够匹配字符"A"后面跟着正好3个数字字符的串,例如A123、A348等,但是不匹配A1234。而正则表达式[0-9]\{4,6\} 匹配连续的任意4个、5个或者6个数字字符。注意:这个元字符不是所有的软件都支持的。& Z% [& m) _* l( z
$ @3 T) q% k. t3 w 最简单的元字符是点,它能够匹配任何单个字符(注意不包括新行符)。假定有个文件test.txt包含以下几行内容: , ~; x; s$ z& i& v' C$ v$ c7 G3 |# k8 |3 D5 {. d# Z
he is a rat: K5 v# n% _1 O4 G: D
! ?, C$ O+ u- ?5 L& K" ?
he is in a rut0 F/ _, p9 F) i9 _! v
/ C! B4 y) R/ U3 z% z( @7 q the food is Rotten : G2 z) B4 G2 ?5 h9 u8 E. A. `+ d$ u# B8 t8 Z4 n" Y1 l
I like root beer ) b4 w6 i; S, {/ T) J E
" V7 k i. N. h4 @. s
我们可以使用grep命令来测试我们的正则表达式,grep命令使用正则表达式去尝试匹配指定文件的每一行,并将至少有一处匹配表达式的所有行显示出来。命令 - r) n4 _! }7 d! W, G0 Z ; w/ S0 C n- x$ s6 b6 p) @; e grep r.t test.txt * F$ V+ x- a5 }# e4 v0 q2 Q. F& m% g \* i1 [$ @
在test.txt文件中的每一行中搜索正则表达式r.t,并打印输出匹配的行。正则表达式r.t匹配一个r接着任何一个字符再接着一个t。所以它将匹配文件中的rat和rut,而不能匹配Rotten中的Rot,因为正则表达式是大小写敏感的。要想同时匹配大写和小写字母,应该使用字符区间元字符(方括号)。正则表达式[Rr]能够同时匹配R和r。所以,要想匹配一个大写或者小写的r接着任何一个字符再接着一个t就要使用这个表达式:[Rr].t。 # q& f- N) g3 k) m& J; _4 g( k1 J4 @. T* o& G8 ^4 i( k
要想匹配行首的字符要使用抑扬字符(^)——又是也被叫做插入符。例如,想找到text.txt中行首"he"打头的行,你可能会先用简单表达式he,但是这会匹配第三行的the,所以要使用正则表达式^he,它只匹配在行首出现的h。 Y, g+ k7 \8 H; h7 O6 a* B# r6 \
9 O0 o% }0 J5 l w, J
有时候指定“除了×××都匹配”会比较容易达到目的,当抑扬字符(^)出现在方括号中是,它表示“排除”,例如要匹配he ,但是排除前面是t or s的情况(也就是the和she),可以使用:[^st]he。' K9 E2 t4 }% {1 j
3 r; x/ V7 a4 E# F 可以使用方括号来指定多个字符区间。例如正则表达式[A-Za-z]匹配任何字母,包括大写和小写的;正则表达式[A-Za-z][A-Za-z]* 匹配一个字母后面接着0或者多个字母(大写或者小写)。当然我们也可以用元字符+做到同样的事情,也就是:[A-Za-z]+ ,和[A-Za-z][A-Za-z]*完全等价。但是要注意元字符+ 并不是所有支持正则表达式的程序都支持的。关于这一点可以参考后面的正则表达式语法支持情况。 2 N6 L, @! w# w; D1 c' z4 o' V2 o5 X$ b7 E
要指定特定数量的匹配,要使用大括号(注意必须使用反斜杠来转义)。想匹配所有100和1000的实例而排除10和10000,可以使用:10\{2,3\},这个正则表达式匹配数字1后面跟着2或者3个0的模式。在这个元字符的使用中一个有用的变化是忽略第二个数字,例如正则表达式0\{3,\} 将匹配至少3个连续的0。 . Z, ?5 s& F+ K3 `) T8 e9 k) E: a" @8 w9 w3 L0 m3 @: a1 |
简单的例子 - j$ G S% `6 f% m ; h. N- t$ X' ?) n, g 这里有一些有代表性的、比较简单的例子。; z/ `0 q! {7 u' @/ w: @( s% }
" C Z8 F$ B1 U5 S3 t
vi 命令 作用 8 m0 R% M" W1 Q4 e- A3 A- ^9 d8 }3 ~$ k$ B4 }' c; t+ E v0 g
:%s/ */ /g 把一个或者多个空格替换为一个空格。 3 y0 F) C( \8 v* S * |- u3 S0 F5 @# Y( N :%s/ *$// 去掉行尾的所有空格。/ R* w I- ~4 }. N0 b) Z
9 b- P `2 @1 u" x2 S
:%s/^/ / 在每一行头上加入一个空格。 1 e1 W. D) v+ k# `% G% Q3 t, @- u3 G0 i q- t; U
:%s/^[0-9][0-9]* // 去掉行首的所有数字字符。 3 d' B! b/ Q+ ]6 P3 t 2 f) {* L/ `* p- ~5 ^ :%s/b[aeio]g/bug/g 将所有的bag、beg、big和bog改为bug。 - Y3 H' y8 J; O' F$ a. \0 K 7 f% f" O$ @/ _. l5 S :%s/t\([aou]\)g/h$t/g 将所有tag、tog和tug分别改为hat、hot和hug(注意用group的用法和使用引用前面被匹配的字符)。. \: d9 P( r! f% ?+ u
" x3 @5 |+ [2 q: U5 Z i awk ' ~ /^[JT]/ ' price.txt 打印所有第二个字段是'J'或者'T'打头的行中的第三个字段" \& q5 }1 s G% d4 A" z" e
- O. D+ q! m- i/ R! ` awk ' !~ /[Mm]isc/ {print + }' price.txt 针对所有第二个字段不包含'Misc'或者'misc'的行,打印第3和第4列的和(假定为数字)( Q& U& d% {6 X- [4 |4 K' f' S
. k S: Q8 j3 _: ]) N% V- ] awk ' !~ /^[0-9]+\.[0-9]*$/ ' price.txt 打印所有第三个字段不是数字的行,这里数字是指d.d或者d这样的形式,其中d是0到9的任何数字 a7 k! u7 H+ Z7 D4 V! }& E+ R2 a& I6 s/ Q* `5 g. D( F
awk ' ~ /John|Fred/ ' price.txt 如果第二个字段包含'John'或者'Fred'则打印整行+ F9 I8 ~. {+ h2 t3 b8 Y
2 ^$ N( M% x @' c8 I- E+ w: y# C
grep& v d. v% ] m+ i
: a/ v: O2 I2 q4 ?: p
grep是一个用来在一个或者多个文件或者输入流中使用RE进行查找的程序。它的name编程语言可以用来针对文件和管道进行处理。可以在手册中得到关于grep的完整信息。这个同样古怪的名字来源于vi的一个命令,g/re/p,意思是global regular expression print。* M" l' @7 x5 [: _% X$ `$ b
2 p9 G0 j* y) v- {. m4 @+ ]
下面的例子中我们假定在文件phone.txt中包含以下的文本,——其格式是姓加一个逗号,然后是名,然后是一个制表符,然后是电话号码:" o. g1 m# j7 J4 R0 q
]3 [0 ]- e! ?( m9 _! |
Francis, John 5-3871 + t! R# Z7 B- w& x- j7 K$ i: T5 q
Wong, Fred 4-4123, C3 w6 ^0 j7 \* l) `% O" z$ Y
4 M5 C) X8 [5 I7 N1 [
Jones, Thomas 1-4122 z- U. o2 k/ x! P- H
8 I( t$ |4 f. e4 H1 g
Salazar, Richard 5-2522, F: T; q$ @4 n: V8 s1 p
3 u; W6 m% F% c( V
grep命令 描述& |) d9 _' Q6 y4 V1 K
& M7 z3 t5 o: h9 V
grep '\t5-...1' phone.txt 把所有电话号码以5开头以1结束的行打印出来,注意制表符是用\t表示的 " J4 A9 Z, ~4 m0 S! Z5 \& Q/ O8 }0 e6 a& |0 M- F6 L2 ?
grep '^S[^ ]* R' phone.txt 打印所有姓以S打头和名以R打头的行 % ~4 _$ O. O0 d# ^ / T/ i9 z. x7 l# {& H grep '^[JW]' phone.txt 打印所有姓开头是J或者W的行 - }6 W' Y- T7 ~9 `* q2 d ! P5 R3 _/ j& H6 } j! @# Z6 f, x grep ', ....\t' phone.txt 打印所有姓是4个字符的行,注意制表符是用\t表示的; T% ^1 x( j( n( R* A
6 g, G# [' k" Z. S. D7 u$ X grep -v '^[JW]' phone.txt 打印所有不以J或者W开头的行 K) f) V( u+ `! j6 U5 g5 R- p! k% u1 C0 W% o
grep '^[M-Z]' phone.txt 打印所有姓的开头是M到Z之间任一字符的行9 Y# q5 }# ~1 V. r
; O/ n+ a( U) u/ q( q
grep '^[M-Z].*[12]' phone.txt 打印所有姓的开头是M到Z之间任一字符,并且点号号码结尾是1或者2的行 4 r! K* L* Z8 N, P" j2 ?" V) f5 Z3 o8 G1 @
egrep 4 U4 X4 a& r; S ) p' {' j- O8 T1 [0 {7 o2 e$ U9 |% h egrep是grep的一个扩展版本,它在它的正则表达式中支持更多的元字符。下面的例子中我们假定在文件phone.txt中包含以下的文本,——其格式是姓加一个逗号,然后是名,然后是一个制表符,然后是电话号码: # {9 |5 ~- {3 {% R4 v0 b' E2 d- s; M0 ~' D+ e2 c
Francis, John 5-38711 H# ~( s: ], j* L D# t4 V4 K
: T' e C. O2 P, e' p! A/ s
Wong, Fred 4-4123" P' e/ _3 B3 o9 X- t
6 V: v) d8 z4 m6 b. W k# K- R3 b* |" R Jones, Thomas 1-41221 L5 O8 w/ ?: l, z# l6 v
' \" C, d- U, W" w9 ~
Salazar, Richard 5-2522 5 l) A3 D1 F, l* L s' c8 h / S) V( l# A0 e; d/ | egrep command Description 9 S4 ]- q2 U# b# w7 q4 a- |# d , t0 R# G! H( e" I# i7 o7 M+ K/ D egrep '(John|Fred)' phone.txt 打印所有包含名字John或者Fred的行8 E7 c" S5 J$ i. k. Y
F' i6 B, q0 O' S egrep 'John|22$|^W' phone.txt 打印所有包含John 或者以22结束或者以W的行 3 V/ H7 R' M9 N+ b ( s: `1 P1 O Y4 ]" R+ E' e egrep 'net(work)?s' report.txt 从report.txt中找到所有包含networks或者nets的行 9 |- l- {7 J: h* P' @6 F- { f2 d. i
正则表达式语法支持情况 e) a5 N: X% U
& h6 l R) h3 e C. T4 k7 [$ i
命令或环境 . [ ] ^ $ \( \) \{ \} ? + | ( ) ' [# o( h- ^) b' G( f* K* P" V2 u8 T: O. G! t5 j4 Q# g
vi X X X X X 6 G0 M) V/ C: Z Y/ K( N
8 ~4 K+ G0 ^! {* p: y; G Visual C++ X X X X X ) R6 M- `' O, d% g: |0 s: p ) |" ^+ ]7 P. M" [: ^ awk X X X X X X X X ' _( ~& o/ M' G7 q
! e$ F4 o, d! ^2 E! e9 Y8 b0 G sed X X X X X X ( X1 f3 f; {& S: X$ @+ L
# H! s$ ]- T+ P% m9 Z1 v
Tcl X X X X X X X X X 8 L9 @1 X1 @" ]6 [ ! g: m' t' B' g/ o/ U ex X X X X X X * t; B) z' {/ R5 j$ h+ Z( s s6 j6 F- f
grep X X X X X X 5 F. |7 d9 Z/ R
$ X+ L- ]$ K+ D8 _" B; m2 X) N. W, [
egrep X X X X X X X X X . _, G$ g8 `8 u/ K) a, F% h- y+ m7 J
$ P: X, K2 q5 F }% k. y fgrep X X X X X ; X' j* J+ e2 k; E$ l1 @0 d) S5 q5 m) p. ~) _: y
perl X X X X X X X X X * m7 ]# P0 I. F( { r+ x& U2 d " P1 X5 l7 ~" ~* D @0 b vi替换命令简介' H, d/ x4 e* W d2 {
. L+ K; S$ n$ B0 s. Z Vi的替换命令: $ k- O0 [0 a& [/ I/ S9 a! J) ^ 6 R# H( W, z' g+ c/ c# U6 A' j :ranges/pat1/pat2/g * G+ R: K! V8 N0 p1 z
# m) H5 r/ c: K
其中4 e3 E6 l* q4 ]; Q4 {# v% D
6 q4 d3 |7 h2 V! Y9 G6 b' Y
: 这是Vi的命令执行界面。 @" B0 N9 x' j% H
8 }. b& R6 C* L
range 是命令执行范围的指定,可以使用百分号(%)表示所有行,使用点(.)表示当前行,使用美元符号($)表示最后一行。你还可以使用行号,例如10,20表示第10到20行,.,$表示当前行到最后一行,.+2,$-5表示当前行后两行直到全文的倒数第五行,等等。 - Y9 j* a4 g! L3 p2 L * j! o- c) D5 F. k s 表示其后是一个替换命令。0 ^" j6 R0 c8 J+ y4 _ ~7 |& G
8 @6 B; h; W4 D4 K& d+ \
pat1 这是要查找的一个正则表达式,这篇文章中有一大堆例子。. m, o. N, l3 L9 |/ j$ J. H4 [
, I, T/ K" b0 b" B
pat2 这是希望把匹配串变成的模式的正则表达式,这篇文章中有一大堆例子。2 I) \) x, ?9 f$ b' u- U* h
7 y4 w8 L1 m( H f: E! I5 x/ e9 J; M+ o6 n g 可选标志,带这个标志表示替换将针对行中每个匹配的串进行,否则则只替换行中第一个匹配串。 9 o( L' y) f; ~. \. U: y/ U9 k[编辑本段] : ~6 |) x# r+ [4 L9 _) |五、常用的正则表达式 6 {9 ]- e$ y# p 常用的正则表达式主要有以下几种:3 o m; G5 e1 d/ s8 G) y& k
: a+ f7 x6 N9 T. B ` 匹配中文字符的正则表达式: [\u4e00-\u9fa5] J; z6 p) F* ]8 ~ 2 z% l M' f5 j) q4 {" A 评注:匹配中文还真是个头疼的事,有了这个表达式就好办了哦; L- K' R% k$ ]7 N
y2 g% E- e; ^3 w' ^ 获取日期正则表达式:\d{4}[年|\-|\.]\d{1,2}[月|\-|\.]\d{1,2}日?$ |9 Z9 F$ W, P! p# L6 ]- L. j! C2 k
& M0 l7 a' S5 z0 F 评注:可用来匹配大多数年月日信息。1 A# c+ K! S- F2 q" ^2 F
2 h$ \7 i6 h& R
匹配双字节字符(包括汉字在内):[^\x00-\xff] / t: S; K3 k' u8 h$ a7 U; t 5 |% a3 U4 [7 q* \8 U 评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)# [: B; N2 P( C1 b z6 ^+ d+ H6 M
7 L* Y9 ?- d& P' @
匹配空白行的正则表达式:\n\s*\r # P1 X* B4 c3 z V. r( s. v' W; X/ I3 {& f8 G$ U8 [
评注:可以用来删除空白行, d! \" L9 x: p; E$ T! g! I
; G2 u$ X0 U4 v9 K. I/ m
匹配HTML标记的正则表达式:<(\S*?)[^>]*>.*?</>|<.*? />. h) {9 [% H. t
4 h6 R Y/ ] _% {/ U2 L( I9 d
评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力1 @% I4 o" A* C3 _, G4 T1 X( e9 U7 F
6 r* r! w( O7 E& n1 r
匹配首尾空白字符的正则表达式:^\s*|\s*$2 [( d' ?: z, C/ V9 J: C* l; L
$ L: g3 D* V$ ^4 V 评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式: z/ S! X0 z, Z
3 c/ v6 ]# @7 C9 `3 \2 Y" q 匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)* * t- t; ~& `$ l/ l% T, K, ]$ v, K! Z t3 N" s2 J9 I8 h x 评注:表单验证时很实用) ]4 i! e3 Z/ a2 E
; N* _! Q3 ~/ S# A: L& E 那么,就把”C:\Program Files\EditPlus 2\“替换成你当前软件的路径。 8 J9 z$ W1 E7 F+ [/ T6 W6 J, h ' ]; p! Q4 Y- }. u 其它提示找不到文件的解决方法同上 / L- j' l. Z9 c5 D; f# N + N% x; C' p8 h; \6 d% z0 } 【10】软件技巧——设置editplus支持其它文字,如韩文5 c) v6 D- P9 `. s" K
; m. Y3 h. w" I# R. q 在editplus里打开文件,出来打开文件对话框;然后点击“转换器”后面的那个省略号,会出来自定义转换器对话框;在右边选择你需要的编码方式,添加到左边,然后点确定;最后在下拉框中选择需要的编码方式,然后打开文件即可。; d; Y1 d! ]" c5 M# L
5 ]7 N, s0 R/ Y5 q7 Z
【11】软件技巧——FTP 上传的设置7 \+ q2 |# k- C, \/ S
' B( ]; {; [, o8 F “文件->远程操作->FTP 上传”在“设置”选项卡中设置好参数(“子目录”前面应该加“/”如“/web/”),点击“确定”回到“FTP 上传”选项卡,然后点击“上传”即可;“批量上传”的设置类似。1 T3 f/ T" J- y; R4 F! U5 c0 l
6 Z5 E# j# ~; W6 d
【12】软件技巧——如何禁用备份文件功能? $ @$ P6 I+ [7 Z" r& n3 j ~& {1 o. p( N( ?! G+ J8 Z
在“参数选择”的文件选项页,禁用“'保存时自动创建备份文件”选项- a. G% u z! q. q: V
4 h$ _$ G/ I1 ` 【13】软件技巧——添加语法文件、自动完成文件、以及剪辑库文件( F Y2 L) p: Q- L G
& h+ u p2 a* A: k
要添加 *.STX(语法文件)或 *.ACP(自动完成文件):4 W% f! n& I& o& X. {+ n0 b! [
! f+ W# H/ t$ ~" }3 s9 M( [3 B) A
1. 选择“参数选择→语法”. y% g& l& l/ [
7 f+ F. I" l& n3 a. B
2. 单击“添加”按钮,命名,在“扩展名”部分输入对应扩展名(不带“.”) 9 l1 c: W7 }6 w. w# s% O- C1 ]/ S + b' g8 O5 b: Y: L% D2 ~ 3. 浏览/输入 STX(语法文件部分) 以及 ACP(自动完成文件部分)。 . j9 u7 Y- s4 G 2 {7 |5 g7 r' _/ g# y+ F 添加剪辑库文件(*.CTL)( w3 [* G$ e& B" L. p* }
; h) {8 |7 Y/ v: |
复制相应 *.CTL 文件到软件安装目录,重新启动 EditPlus ,则系统自动识别。$ @5 l0 s6 E! X, f4 w2 e
T3 q0 U9 b: S) e 菜单文本:编译 nsis0 I5 L9 Q6 {7 [4 T0 p
* D0 I9 z! c, K w! ~! a6 u9 c+ j
命令:C:\NSIS\makensis.exe 6 C# y* @ p0 C/ R8 B$ ^! {! z 0 C; q% S% W% r9 P7 z* S 参数:$(FileName) / G, I; w) h! q( p7 z: K + S+ |$ B+ Z1 K- ? 初始目录:$(FileDir) f# }0 T. |) T# g# | {7 ~( P2 `( `/ W# b# ~9 A 捕获输出:开启 & A# @8 p7 J+ T- O$ f 3 i3 [" h- W( v- C* ~% M 例子 6. C#- \2 }+ Z; i. O: ?- t$ F6 y2 v
) z( q1 L/ G( Z9 b 菜单文本:编译 C# ! ]4 N) T; O$ T+ P * W6 S, b5 m' a2 i; M 命令:C:\WINDOWS\Microsoft.NET\Framework\v1.0.3705\csc.exe- R/ U8 z% Z4 M6 C3 ]; H x* R- C M
% j# m3 C2 q3 ^! I% ?
参数:$(FileName)% @) ^$ \; C0 E5 @1 N
7 e- q" K* ?) E. M
初始目录:$(FileDir)4 P9 s/ } P2 y7 l/ J" C
. p2 l' b' Y X# I) h! { 捕获输出:开启 3 A, m, n8 N! j( V+ Q% M1 g! z: b" i' M& H0 O
在上面设置中,在命令部分,必须使用系统中各自编译器的绝对路径。 7 ` J# H/ J; h6 x: R4 n2 `7 i3 g! h7 n4 z/ z+ _$ o7 b
设置完毕后,你可以在“工具”菜单运行对应工具了,运行结果会显示在底部的输出窗口,你也可以通过快捷键(Ctrl + 0-9) 运行,或者是通过“用户工具栏”的快捷按钮运行。* Z0 j$ U. {% I# t
+ v+ l$ Q3 N8 H( ]4 s' @( u6 W# G- q 要运行已编译的 *.exe 文件,你可以进行如下设置(此时可执行文件需要和编译文件同名): ( Y2 Z' Z) g. v& \: n- S, N/ e, d0 o# f$ V" w$ M
菜单文本:Run " r8 t# I5 Y4 c8 d! `7 ?" J. t/ g, U6 K& L0 t+ k6 S
命令:$(FileNameNoExt) ! e; N- |: T! t2 H; j2 X8 Y& ^) U" }$ i
参数:4 Y6 h" V7 o: Y- c7 Z; l
& o' l. r5 e0 ?5 v
初始目录:$(FileDir)7 s% \; Y$ U" K! g
& t# I4 S2 e7 z) `
【15】工具集成—— 让Editplus调试PHP程序 - B" _0 y' r# [/ R- K6 k7 K7 M: D! a
1:打开Editplus,选择"工具->配置用户工具..."菜单。; `# l& P" q8 }8 _% s) y4 k
* f9 C: j: Y& k& l
2:在弹出的窗口中选择"添加工具->应用程序",给新程序起一个好记的名字,比如这里我们用"Debug PHP",在"菜单文本"中输入"Debug PHP"。点击"命令行"右边的按钮,找到你的php.exe所在的路径,例如这里是"c:\php\php.exe"。再点击"参数"右边的下拉按钮选择"文件路径",最后再把"捕获输出"前面的复选框选上。 1 l2 B! B+ [8 Z5 q4 {4 b, \9 ?8 t
3:现在测试一下,新建一个php文件,按快捷键Ctrl+1可以激活刚才我们设置的工具(如果你设置了多个工具,快捷键可能会有所不同),现在你可以看到它已经能正常工作了。但是还有一点不太理想:如果你的PHP程序出错,在输出窗口会提示你第几行出错 ,单击这一行提示,Editplus老是提示你找不到某某文件,是否新建。接下下我们要修正这个功能。- h0 C2 T0 a$ \" [5 h
9 M6 D) o" ~3 B- P/ m$ {# |
4:打开刚才用户工具设置窗口,找到刚才设置的"Debug PHP"工具。点击"捕获输出"复选框旁边的"输出模式"按钮,会弹出一个定义输出模式的窗体,把"使用默认输出模式"前面的复选框去掉, 在"正则表达式"这一项的文本框中输入" ^.+ in (.+) line ([0-9]+) "(不包括引号),细心的朋友可能会发现,这里使用的也正则表达式的语法。然后,在下面的"文件名"下拉菜单中选择"预设表达式 1",即上边正则表达式中的第一个参数,"行"下拉菜单项选择"预设表达式 2","列"下拉项保持为空。然后保存设置。 : N" g5 ]0 u% ?' O- U# p3 B* T! }2 y7 B0 @& R
5:好了,现在再来试一下吧,双击出错的行数,Editplus就会自动激活出错文件,并把光标定位到出错行,是不是特别方便呢?! ( a/ _+ h8 X7 r3 }6 o 0 W+ z* b+ x3 l: W 现在,Editplus经过我们的"改造",已经可以即时的调试PHP文件了,虽然还不是"可视化"界面的,但对于一些平常的小程序来查错还是非常好用的。Editplus真是不款不可多得的好工具,如果你有什么使用技巧,不要忘了大家一起分享哦。^O^) p( K. E. c! u) r; h
$ c1 C- v7 Z5 w+ n
如果不能切换错误行号,请尝试作如下修改: (by aukw@CCF)4 @: P& f9 [! T D0 P2 Y
$ M( g* J5 r7 E9 x6 ?$ c
1.php.ini 中html_errors = Off打开 2 Q% C! r5 E# Q7 K3 o8 l i/ P% V& R2 k( I8 X4 x
//如果你不打开,3.中的表达式要修改 . R5 O( X& k# f1 P $ s! T$ ~4 C$ F* W 2.参数改成:-q -f "$(FilePath)" $ h5 h% b. b. O . _% A, q1 a1 k" R9 R; X7 b) T //不加"符号的话文件名有空格的文件调试失败。。$ e) |+ J/ I2 D3 U S
; H i; u1 `7 @: z9 S! p //-q不输出html头信息,你去掉也行,不过调试时候你一般用不到那些header信息* j ]. R! t3 D
$ @; R2 Y% l# Y- g8 h: n
3." ^.+ in (.+) line ([0-9]+) " 改成 "^.+ in (.+) on line ([0-9]+)$" 9 X1 d' g, i7 s9 `& ~+ E' K; r; t# Y& \ " v% ~; W% p8 S4 v //如果还是不行,请注意调试结果,自己修改表达式来取出文件名和行号* g4 ^, l" w1 |6 w5 W) k
/ e; e- g( K5 g' g 【16】工具集成——打造 PHP 调试环境(二) $ h" Z( f. n4 d! O1 l! q& w; w" Y. E4 R& z
1: 把剪辑库定位在 PHP4 Functions 上就可以在编辑时, 利用[插入]->[匹配剪辑]命令,就可以自动完成末输入完整的 PHP 函数(或直接按 F2 键)3 u6 @' e5 I8 e/ v8 d0 S" X5 A
" J& P1 g" B$ A) w" b1 W
2: 类似上面,在选择部分文字后,同样可以自动完成。(同 F2) ; ?4 M: p1 i, K1 C3 w2 g; ~* E u. m/ i% }0 h. K1 N* E6 c# Z 3: 在[参数选择]->[设置和语法]->PHP->自动完成, 选择目录下的 php.acp 文件,你可以定制自己的自动完成方式. * z& q$ i$ F0 [0 X- o ( e& ^ E1 d) @0 U' a- z/ \ 4: 想要即时预览文件,可在[参数选择]->[工具]->WEB 服务器中添加本地目录,(注意不要加 http:// , 应是一个有效的站点)。! T1 q: a3 D& K* q
( _' ?( e( a7 r( D m4 W: J8 {
如: 主机->localhost/php | 根目录->D:\php: p) n9 p1 R: }; Q |4 b+ Q9 F
9 K4 j' O+ b& v5 y3 ]
主机->localhost/asp | 根目录->D:\asp . ]# \- I" w: {) w; v$ I" D0 e8 b B' @- E! ^& k
主机->localhost/cgi | 根目录->D:\cgi 6 v) |. s- u0 a! C9 X" \, L8 \+ l3 } ~/ H
完成设置后只要脚本文件位于这些目录下(子目录也没问题), 就能够正确解释. ; B5 d6 e1 i1 L6 y1 q, P) a+ C# ~' D2 ?& M& e; Z: U
5: 各种语法和模板文件可以在 http://editplus.com/files.html 获得,可根据需要选用和编辑。 3 ]. q5 N' f: k: W- ~ 0 d% @" d7 t) z$ G% Y4 m2 I" q 6: Ctrl+F11 可显示当前文件中的函数列表. # \! y R3 f, |# e, {2 N) T( f$ K9 r. d' [8 r, W6 P
7: 添加各种用户工具.如:9 d5 g. W1 f# s4 [9 Z1 C3 c
2 X' j/ G" H L1 V; A% B `
启动MYSQL服务器管理工具->C:\mysql\bin\winmysqladmin.exe, n: f$ P& M, R; y2 [7 v
6 h$ h; P9 \ y( }: }6 D' g+ a 启动Apache服务器->C:\Apache\bin\Apache.exe -k start& M- e& U: T* }/ L1 s
, o: D; m5 I/ L, ?
启动Apache服务器->C:\Apache\bin\Apache.exe -k stop (shutdown)' c& Y9 X' X5 `$ s, w2 a
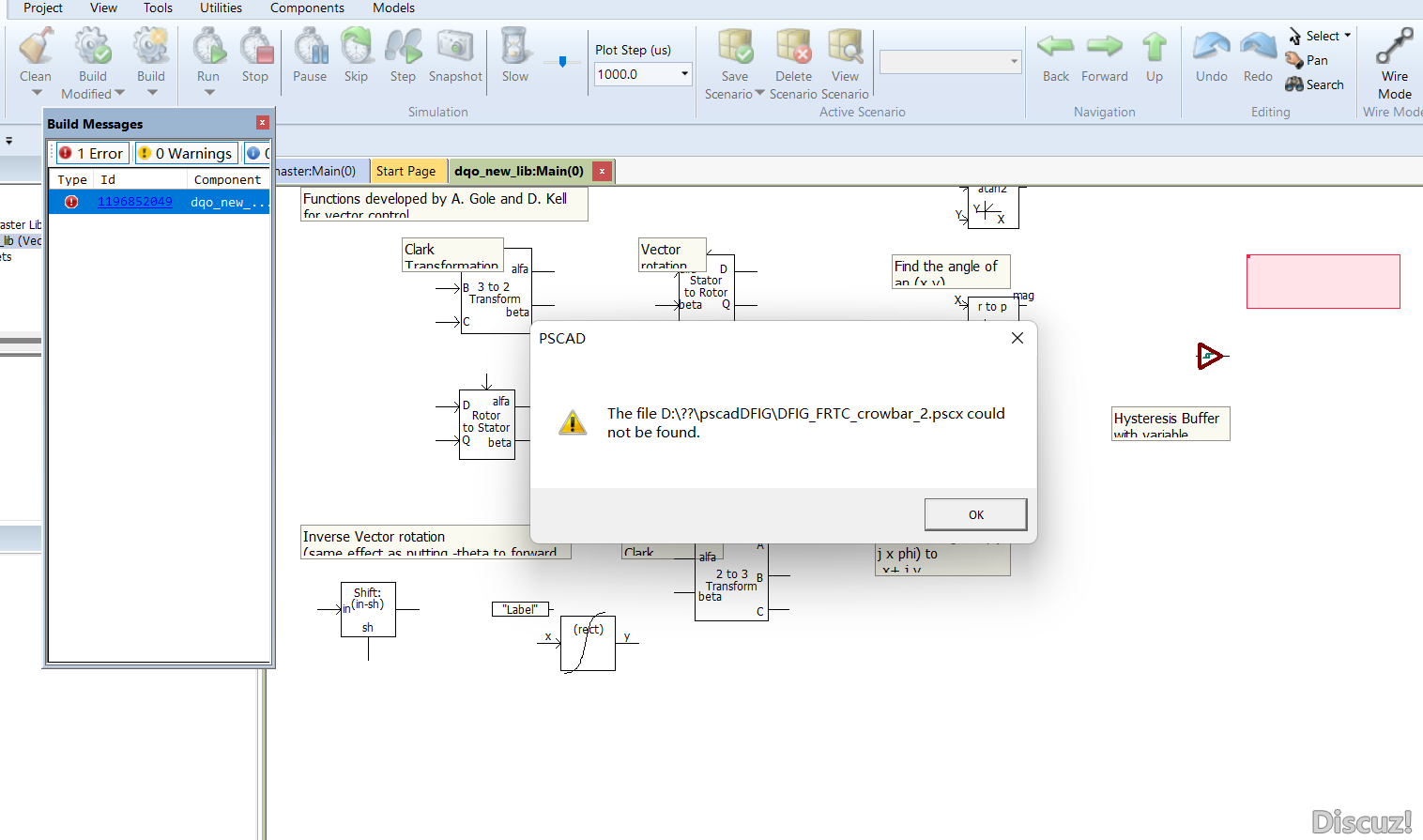
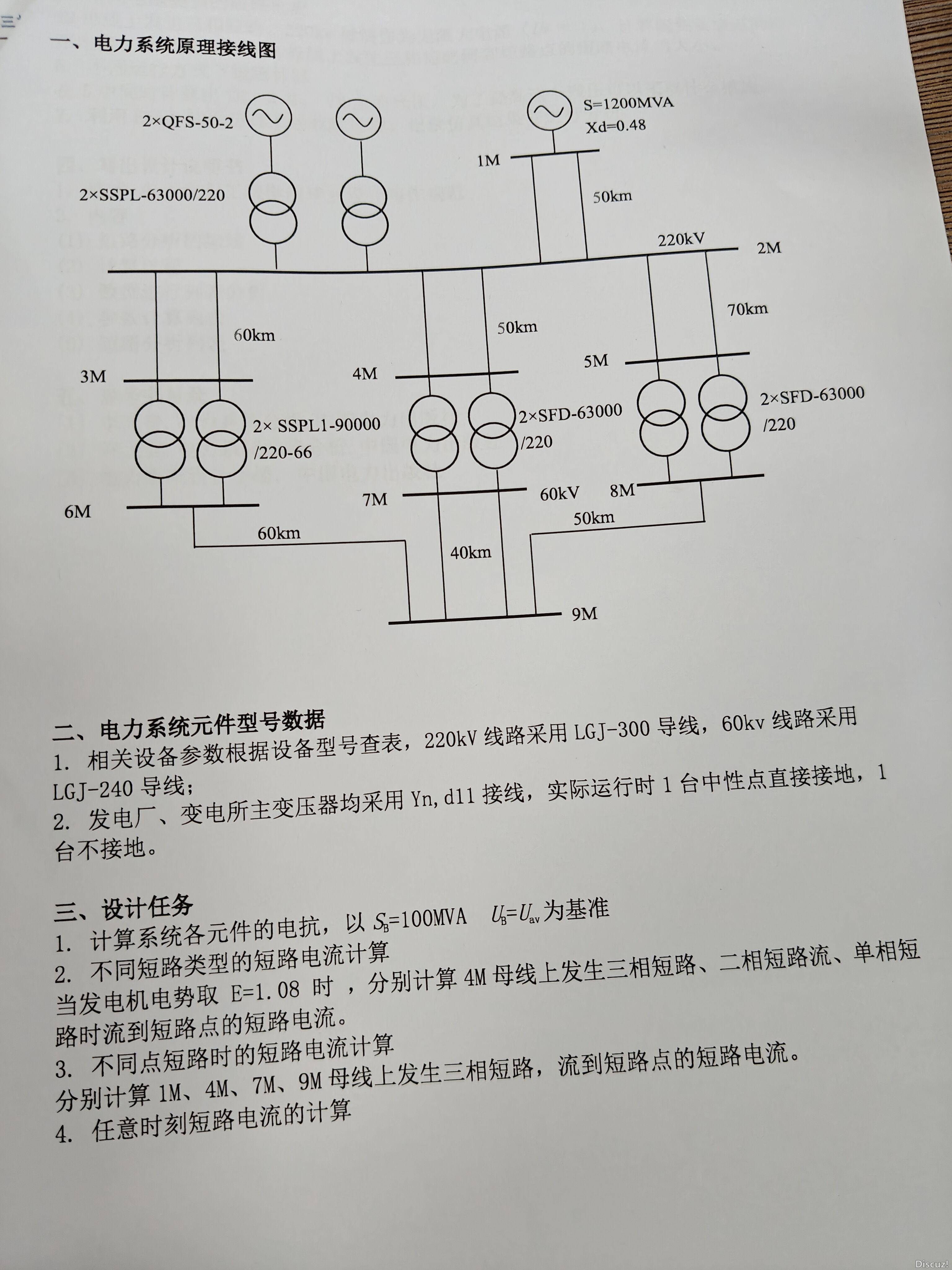



 狗仔卡
狗仔卡
 发表于 2010-5-10 08:27:02
发表于 2010-5-10 08:27:02
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡